如何识别百度蜘蛛,教你正确检测百度蜘蛛的方法
作者: 葛屹肃 | 日期: 2019-11-12 | 分类: 个人杂谈
最近查看网站日志时,总是发现百度蜘蛛抓取一些网站不存在的目录,而且每次所访问的的网址完全一致,这就奇怪,日志如下:
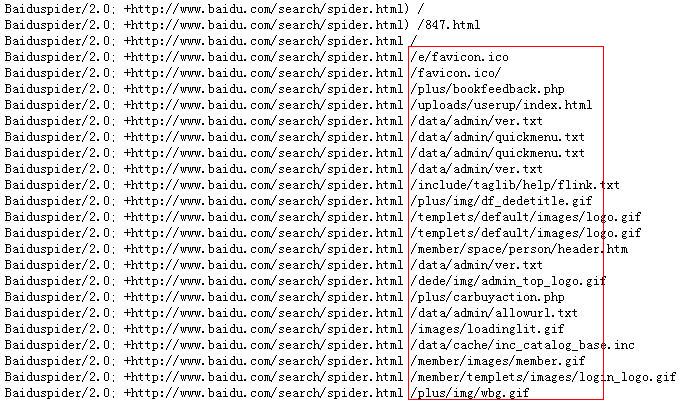
如上图所示,红圈中都是网站不存在的目录或网址,而且之前已经加入robots.txt文件屏敝处理过,为何还会出现呢?
于是,我搜索关于检测百度蜘蛛的方法,发现可以使用nslookup ip命令反解ip来 判断是否来自Baiduspider的抓取,Baiduspider的hostname以*.baidu.com 或*.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充。马上修改了蜘蛛日志记录下访问IP,很快,又出来访问非网站的网址。马上,使用nslookup命令检测,结果如下:

第一个IP是百度蜘蛛正常访问的IP,第二个是来自于访问不存在网址的IP,对照一下,可以明显看出,第二个绝对是模似百度蜘蛛的。是其他爬虫。
那么,问题来了,如何防止其他爬虫访问呢?我看过日志,爬虫的IP是经常变动,并不能设置IP访问限制解决。目前来说,还没有有效的办法能防止爬虫的恶意抓住网站。
版权声明:本文由〖葛屹肃〗发布,转载请注明出处!
文章链接:https://www.geyisu.com/1146.html
文章链接:https://www.geyisu.com/1146.html
